正则表达式核心概念和实践
正则表达式核心概念和实践
Section titled “正则表达式核心概念和实践”正则表达式核心就是对两个东西的匹配:
- 字符;
- 位置;
对字符的理解一般大家都有理解,毕竟他是看得到摸得着的,接下来我对对位置的匹配这一个抽象的概念进行描述。
对位置的理解
Section titled “对位置的理解”要记住,空格不算位置,
'' !== ' ', 空串才算位置'',也就是str.length === 0。
let str7 = 'Hello World!',对于这串字符他的位置都有哪些:
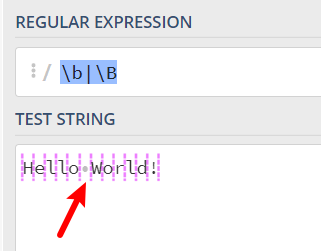
由这个图我们也可以发现中间的空格并不算位置。
既然空串就算做位置的话,那么我可以发现一个特征就是,无限位置的累加并不会对字符有什么影响,这对后面写正则有很多用处。
let str7 = "Hello World!";
// 说明位置是 ''空串, str.length === 0, 位置的累加(也就是空串的累加)并不会影响到原始字符let str8 = "" + "" + "" + str7 + "" + "";console.log("str8 === str7: ", str8 === str7); // true
let str9 = "He" + "" + "llo" + "" + "" + " Wor" + "" + "ld!";console.log("str9 === str7: ", str9 === str7); // true
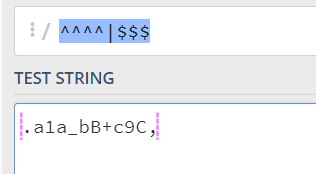
// 再次说明 空格 ' '不算做位置let str10 = "Hello World!" + " ";console.log("str10 === str7: ", str10 === str7); // false所以在正则中也是这么理解,let RE = ^^^^|$$$,多个相同位置的匹配,匹配的也就是同一个地方,他并不会变出来多个开头,或者多个结尾。
对位置的匹配
Section titled “对位置的匹配”-
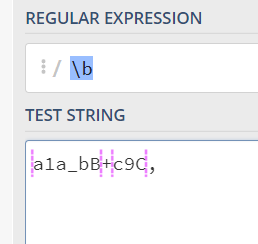
\b, \B-
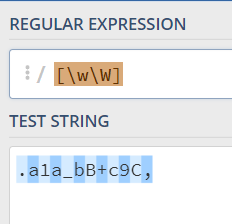
\b代表字符和非字符之间的位置,就是\w和\W, ^, $的间隔的位置, 其中\w代表的是[0-9a-zA-Z_],\w代表的就是\W取反: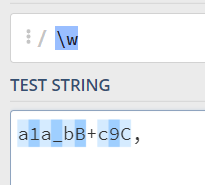
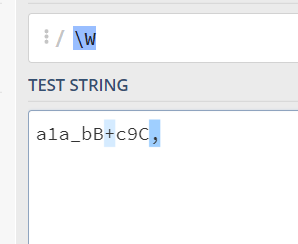
寻找
\b的技巧: 先找到\W, ^, $, 然后看\W, ^, $旁边有没有字符\w, 他们俩之间的位置就是\b -
\B代表非字符间隔的位置,就是和\b取反,除了\b的位置,其他的都是\B的位置: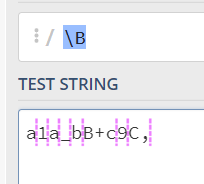
-
-
^, $-
在没有修饰符
m(multiline)的情况下,代表的是所有字符(也就是即使有换行,他也把所有字符看作为一行)的首和尾,也就是不管怎么回车换行找到最后面作为$: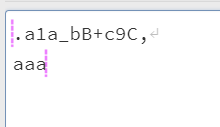
-
在有修饰符
m(multiline)的情况下,代表的是每一行的首尾: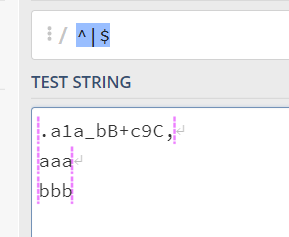
-
-
(?=RE), (?!RE)-
正向先行断言,负向先行断言都需要写在
()里,不然不会生效; -
(?=RE)正向先行断言,代表的含义是这个位置的后面必须满足RE表达式,或者理解为满足RE表达式的前面的位置;比如:
(?=([0-9]|abc))的含义是这个位置的后面要满足([0-9]|abc),也就是这个位置的后面要是数字或者(abc字符串)---这个abc是一个整串: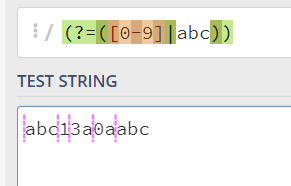
-
(?!RE)负向先行断言,代表的含义是这个位置的后面必须不能满足RE表达式,或者理解为不能满足RE表达式的前面的位置;比如:
(?!=([0-9]|abc))的含义是这个位置的后面必须不能满足([0-9]|abc),也就是这个位置的后面不能是数字或者(abc字符串)---这个abc是一个整串: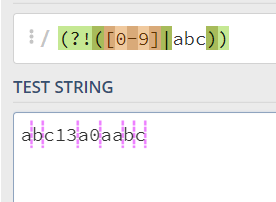
-
-
(?<=RE),(?<!RE)-
正向后行断言,负向后行断言都需要写在
()里,不然不会生效; -
(?<=RE)正向后行断言,代表的含义是这个位置的前面必须满足RE表达式,或者理解为满足RE表达式的后面的位置;比如:
(?<=([0-9]|abc))的含义是这个位置的前面要满足([0-9]|abc),也就是这个位置的前面要是数字或者(abc字符串)---这个abc是一个整串: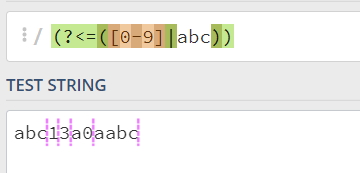
-
(?<!RE)负向后行断言,代表的含义是这个位置的前面不能满足RE表达式,或者理解为不能满足RE表达式的后面的位置比如:
(?<!([0-9]|abc))的含义是这个位置的前面不能满足([0-9]|abc),也就是这个位置的前面不能是数字或者(abc字符串)---这个abc是一个整串: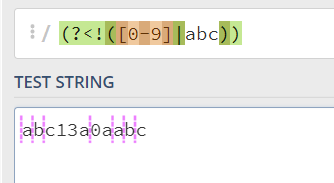
-
这里就是对位置的匹配的应用。
const thousandsSepRE = /\B(?=(\d{3})+$)/g;const handleThousandsSep = (str) => str.replace(thousandsSepRE, ",");
let str3 = handleThousandsSep("123");console.log("str3: ", str3); // 123let str4 = handleThousandsSep("1234");console.log("str4: ", str4); //1,234let str5 = handleThousandsSep("12345678");console.log("str5: ", str5); // 12,345,678let str6 = handleThousandsSep("1233456789010");console.log("str6: ", str6); // 1,233,456,789,010最前面的\B是防止当 str = '100' 然后将开头也匹配到,变成 ',100'。
这里也可以写成 (?!^),也就是这个位置的后面不能是开头, 这里怎么理解呢?
我们先来看(?=^),这个位置的后面必须是^,前文我们描述过,多个同个位置的叠加还是同一个位置(对同一个位置的不同描述)。
那么什么位置的后面是^呢,那就是开头的前面的位置,开头的前面的位置还是开头,例如:'' + '' + '100' === '100':
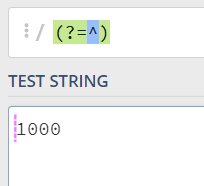
既然理解了(?=^),那就再来看(?!^),这里代表当前位置的后面不能是^,除了开头的后面是开头之外,其他任意地方的位置的后面都不可能是开头:
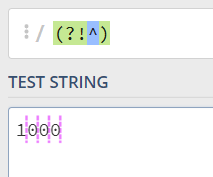
这里有没有人在想为什么不能[^^],或者 [^(?=^)],这是因为[]作为字符组符号,里面写正则表达式只能匹配字符,如果匹配位置是不会生效的。
校验密码格式
Section titled “校验密码格式”综合应用,对位置的匹配和对字符的匹配。
验证密码问题:
密码长度 6-12 位,由数字、小写字符和大写字母组成,必须至少包括 以上2 种类型的字符。
这里我们分步求解:
-
密码长度
6-12位,由数字、小写字符和大写字母组成,const RE1 = /[0-9a-zA-Z]{6,12}/: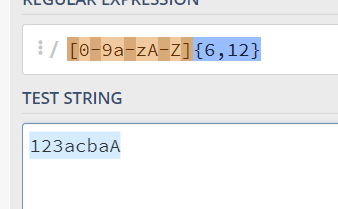
-
密码中必须包含数字:
-
匹配一个位置,这个位置的后面必须包含数字,且这个位置要在开头,因为我们需要这个位置的后面包含所有的字符串:
-
首先怎么写一个匹配开头位置的正则,前文我们知道,字符串的开头是用
^表示,然后^的前面其实也是^,这里我们假设(REForLocation)是一个匹配位置的正则。那么
(REForLocation)^就代表(REForLocation)匹配的位置是字符串的开头;把位置的匹配写在 ^ 之前的话意味着, 可以匹配后续所有的字符串 (?=RE)^ —> 这个位置的后面必须满足 RE —> 整个字符串必须满足 RE
-
接下来写一个包含数字的正则:
.*\d; -
然后结合正向先行断言,来让这个位置的后面包含数字,最终得到
const RE2 = /(?=.*\d)^/,也就是说开头位置的后面必须包含数字;
-
-
写一个密码长度
6-12位,由数字、小写字符和大写字母组成,且密码必须包含数字的正则(我们只用把前文所说的两个正则合并就行RE1 + RE2),const containNumRE = /(?=.*\d)^[0-9a-zA-Z]{6,12}$/;
-
-
那么至少包含两种字符又怎么描述呢?
- 如何表示至少包含数字:
/(?=.*\d)/这个位置的后面必须包含数字 - 如何表示至少包含 a-z:
/(?=.*[a-z])/这个位置的后面必须包含[a-z] - 如何表示至少包含 A-Z:
/(?=.*[A-Z])/这个位置的后面必须包含[A-Z]
因为位置是可以叠加的, 这也就着可以类似于写 ‘and’ 条件拼接:
- 同时包含数字和小写字母
/(?=.*\d)(?=.*[a-z])/ - 同时包含数字和大写字母
/(?=.*\d)(?=.*[A-Z])/ - 同时包含小写字母和大写字母
/(?=.*[a-z])(?=.*[A-Z])/ - 同时包含数字、小写字母和大写字母, 这个要结合最后一个
[0-9a-zA-Z]来看, 没有[0-9a-zA-Z]的话, 同时包含两种, 那就意味着只要有这两种, 然后加其他的任意都可以 - 以上的 4 种情况是或的关系(实际上,可以不用第 4 条)
- 如何表示至少包含数字:
-
最终得到正确答案,密码长度 6-12 位,由数字、小写字符和大写字母组成,但必须至少包括 2 种字符:
const validatePasswordRE =/((?=.*\d)(?=.*[a-z])|(?=.*\d)(?=.*[A-Z])|(?=.*[A-Z])(?=.*[a-z]))^[0-9a-zA-Z]{6,12}$/;validatePasswordRE.test("abcaaa1"); // truevalidatePasswordRE.test("abcAABa"); // truevalidatePasswordRE.test("abcABC123"); // truevalidatePasswordRE.test("A1234AB"); // truevalidatePasswordRE.test("aaaaaaa"); // false 只包含一种字母validatePasswordRE.test("abc1---"); // false 虽说包含三种字符, 但是---不在我们的验证之列
[]是不能匹配位置
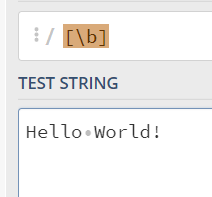
Section titled “[]是不能匹配位置”[]算作字符组,里面写匹配位置的正则不生效,比如[\b], [$], [\B]等,既然[]这个名字叫做字符组的话,那里面肯定写的就是对字符的匹配的正则表达式了:
| 分支符写在哪
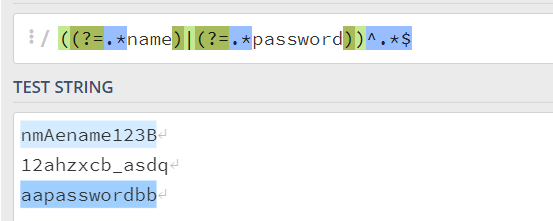
Section titled “| 分支符写在哪”示例,判断一个字符串是否包含name或者password关键字:
-
错误示范
const containNameOrPwdRE = (?=.*name)|(?=.*password)^.*$这里被分支符给分成两个部分,
(?=.*name),(?=.*password)^.*$他这里会先去匹配
(?=.*name)这个正则,也就是先去找后面是name整串的位置。这个找完之后如果不满足,就会去走下一个分支。
也就是匹配下一个正则
(?=.*password)^.*$,开头位置后面包含password整串的这个位置,结尾是任意字符的这个整串,也就是说这个字符串必须包含password,这里显然和我们预期不符: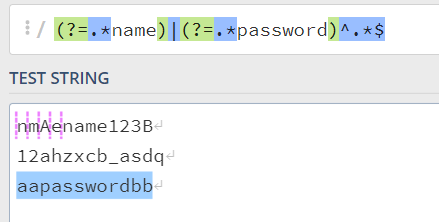
-
正确示范
const containNameOrPwdRE = ((?=.*name)|(?=.*password))^.*$这里被分支符给分成两个部分,前面一个分支不满足,就会匹配后面一个分支,
(?=.*name)^.*$,(?=.*password)^.*$