事件循环
为什么和是什么
Section titled “为什么和是什么”首先我们知道,JS是单线程的,因为它最早是用来实现页面交互的,如果设计成多线程,那么在用户的操作过程中很可能会触发一些互斥操作( 比如操作DOM造成渲染出错),而要处理这些边界情况,复杂度和易错程度将大大上升。
因此为了稳定和简化的目的,JS就被设计为了单线程。
那么随之而来,又遇见了一个问题,由于当前JS的是单线程的,那么执行就是按照执行栈的顺序逐步执行,那如果执行栈中的某一个步骤是耗时操作,或者直接就卡死了呢。
那就会导致整个JS的执行被卡住,并且JS执行所在的线程和GUI线程是互斥的,JS线程直接卡死了,但是它依旧会占据资源,也就导致了GUI线程被冻结而无法正常绘制界面。
为了解决上述的问题,这里就需要添加一层调度的逻辑,能够让JS执行异步操作并且能够去协调这些异步的任务,让其和同步任务能够很好的在一起执行,这种调度的逻辑从某种意义上来说就是事件循环。
有很多人不理解事件循环,就是因为搞不清楚事件循环本质是什么,它和JS的关系又是什么?
事件循环的本质是一个 JS 宿主环境协调各类事件的机制(一般来说,这些事件都是异步的),比如对于浏览器而言,就包括用户交互,脚本,渲染,网络等各类事件;但是对于Node而言,那主要就是协调IO,网络等各类事件。
也就是说事件循环并不是JS内部自己实现的,而是由它的宿主环境实现的,并且由于宿主环境各自的应用场景的不同,它们实现的事件循环也会略有差异。
浏览器的事件循环
Section titled “浏览器的事件循环”事件循环执行流程
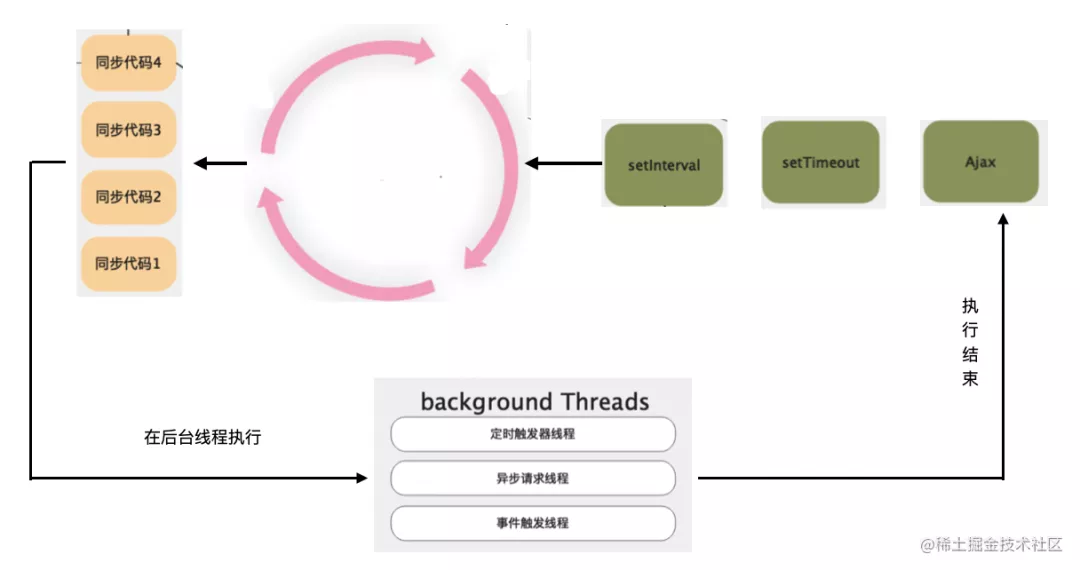
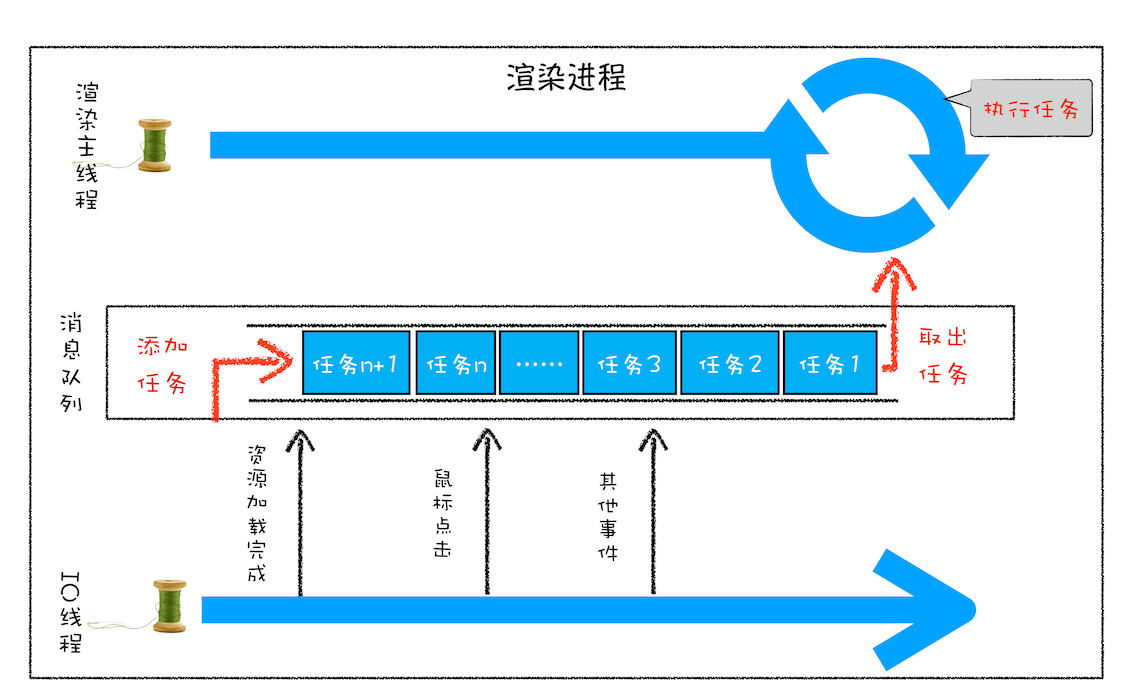
Section titled “事件循环执行流程”浏览器将JS中的执行的任务分为异步任务和同步任务,同步任务就会阻塞执行栈,异步任务一般不会阻塞执行栈,而是由渲染进程的其他线程处理,处理好之后再丢到队列中等待执行栈调用。
比如xhr直接交给异步网络请求线程处理,setTimeout, setInterval直接交给定时器线程处理等,等到这些耗时的任务有结果之后,事件处理线程会将这些任务的回调函数丢到一个队列中(事件队列)。
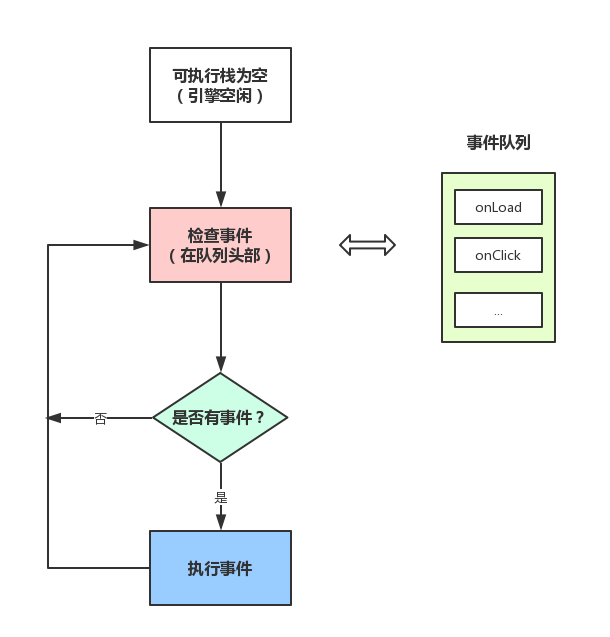
然后渲染主线程会维持一个无限循环,当JS执行栈为空时,这个循环就会去读取事件队列的首部(先进先出),将这个队列中的任务往执行栈中扔,当执行栈再次为空时,该循环开始读取下一个任务,无限往复。这就是事件循环。
宏任务和微任务
Section titled “宏任务和微任务”但是这种还会有一些问题,目前任务队列中的任务是没有优先级之分的,所有被异步线程处理好之后的任务都被塞到任务队列中,等待执行栈的调用,无法进行额外的插队操作。
那如果我们有一些高优先级的任务要执行怎么办,比如类似 MutationObserver,它是用来监听DOM变化的API,一般这种API对实时性要求都特别高,如果我们还得耐心的等着任务队列中前面的任务执行完再执行这个,那可能会得到错误的结果。
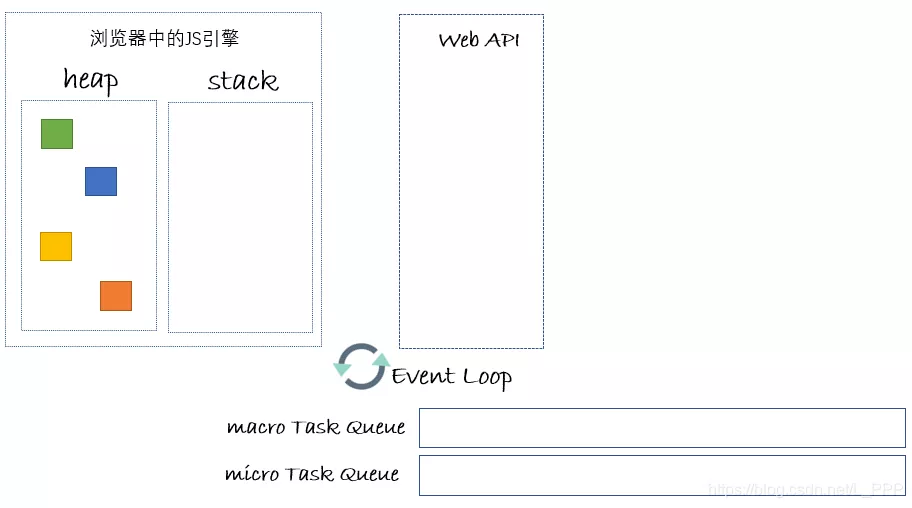
因此浏览器对任务做出了划分,分别为宏任务和微任务;对队列也做出了划分,一个是宏任务队列,一个是微任务队列:
常见的宏任务:
script,对于浏览器而言,JS脚本的执行就算一个宏任务,如果HTML中有多个脚本,那就算多个宏任务;setTimeout/setInterval;setImmediate(仅在IE的一些版本支持);I/O;UI Render;postMessage(可以结合MessageChannel);
常见的微任务:
Promise.then(catch, finally...);Object.observe(已经废弃);MutaionObserver;
那这两个任务队列,浏览器又是如何调度执行的呢?
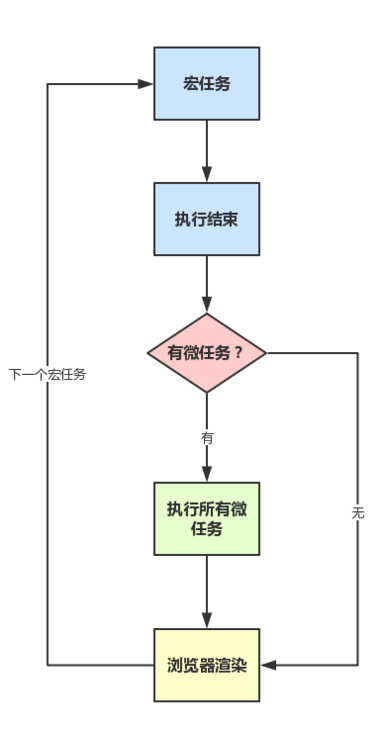
为了能够让微任务高优先级执行,执行情况如下:
-
执行流程以宏任务开始,因为
JS的执行对于浏览器来说就是宏任务,当开始的宏任务执行完之后(当调用栈为空时)开始执行步骤2; -
检测微任务队列是否为空,若不为空,则取出一个微任务入栈执行,然后再次执行当前步骤直到当前微任务队列为空;当微任务队列为空时,开始执行下一轮事件循环,执行步骤
3; -
检测宏任务队列是否为空,若不为空,则取出一个宏任务入栈执行,宏任务执行完之后,当前执行栈为空了,然后执行步骤
2;若宏任务队列为空同样也是执行步骤2; -
2和3这两个步骤反复循环;
举一个例子:
<script> console.log("1");
setTimeout(function callback() { console.log("2"); }, 1000);
new Promise((resolve, reject) => { console.log("3"); resolve(); }).then((res) => { console.log("4"); });
console.log("5"); // 1 3 5 4 2</script>执行顺序如下图:
-
首先最先将整个
script中的JS脚本当作一个宏任务开始执行; -
然后开始执行这个宏任务中的同步代码;
-
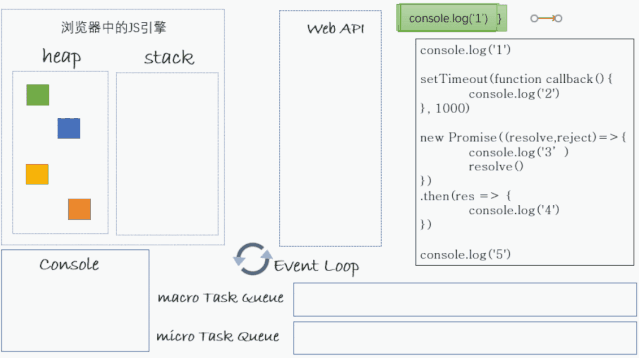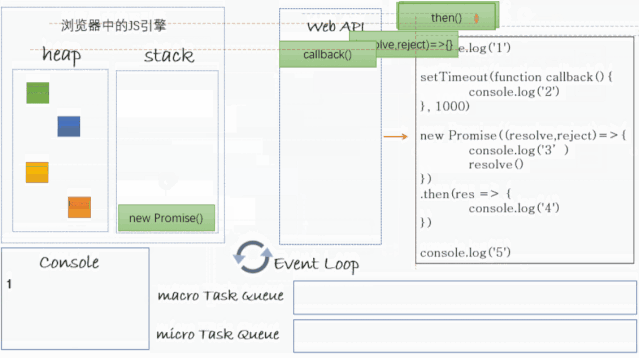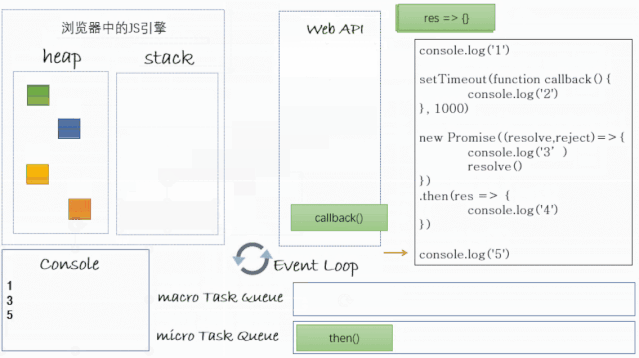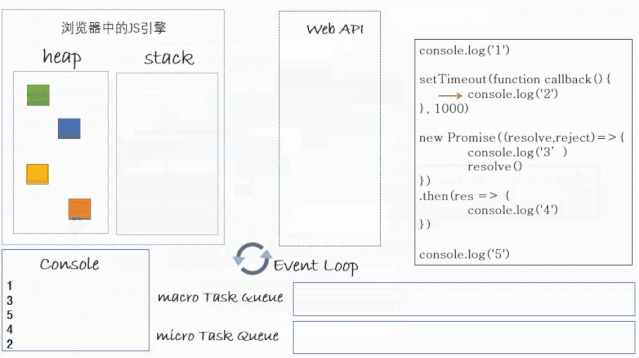
将
console.log('1')推入执行栈中,输出1之后,然后弹出执行栈; -
将
setTimeout推入执行栈中,然后setTimeout中的callback被扔给了浏览器渲染进程的定时器处理线程,1000ms之后定时器处理线程会将其放到事件队列中等待执行栈调用,然后setTimeout弹出栈; -
将
new Promise(xxx)推入执行栈中,然后(resolve, reject => { console.log('3'); resolve() })推入执行栈,then(xxx)被扔给异步线程处理,等待当前Promise状态发生改变,然后才会被放入微任务队列等待执行栈调用;然后
console.log(3)推入执行栈,输出3,console.log('3')弹出栈,resolve()推入执行栈,Promise状态发生改变,然后then中的console.log('4')被扔到微任务队列中等待执行栈调用,resolve()弹出栈,new Promise(xxx)弹出栈; -
将
console.log('5')推入执行栈中,输出5之后,然后弹出执行栈; -
此时这个宏任务中的同步代码就执行完了,也就是说执行栈为空了,此时要开始检查微任务队列中是否还有任务没,发现里面有一个
console.log('4'),将其推入执行栈,输出4之后,弹出栈,此时再次检查微任务队列发现已经没了; -
然后开始下一轮事件循环,此时开始检查宏任务队列,这里有一个
1000ms之后被放入宏任务队列中的任务,从setTimeout之后就开始计时(也就是步骤4那一刻),当其被推入宏任务队列后,如果此时刚好执行栈和微任务队列又都是空的,那么就开始执行callback函数,将callback推入执行栈,然后将console.log('2')推入执行栈,输出2之后,console.log(2)弹出栈,callback弹出栈; -
流程完毕;
Node 的事件循环
Section titled “Node 的事件循环”Node 和浏览器任务体系的差异
Section titled “Node 和浏览器任务体系的差异”浏览器与 Node 的事件循环是存在差异的,这主要是因为两者各自的应用场景不同。
浏览器端主要的应用场景是用户交互,页面渲染,网络请求等;而Node的应用场景则是文件IO,网络请求等,而不用考虑渲染相关。
因此两者的宏任务和微任务也有所差异:
浏览器端:
- 宏任务:
setTimeout、setInterval,用户交互——鼠标、键盘,网络请求——ajax, fetch...,postMessage等; - 微任务:
Promise.then(catch, finally)...,MutaionObserver(监听DOM变化),Object.observe(已经废弃)等;
Node端:
- 宏任务:
setTimeout、setInterval、setImmediate等; - 微任务:
Promise.then(catch, finally)...,process.nextTick等;
而且还有一点很重要的是Node本身是用来设计给服务器用的,服务器对性能,时间等的精确程度要求比浏览器更加细腻一点,因此如果直接用浏览器那一套Event Loop来用肯定是不行的,略显粗糙。
浏览器的事件队列对于优先级的划分只有两层,那就是微任务,宏任务;宏任务和宏任务,微任务和微任务之间是没有额外划分的。
而这里我们的Node在具有宏任务,微任务的前提下,对宏任务和微任务自身也做了优先级的划分,它们各自执行在事件循环的不同阶段。
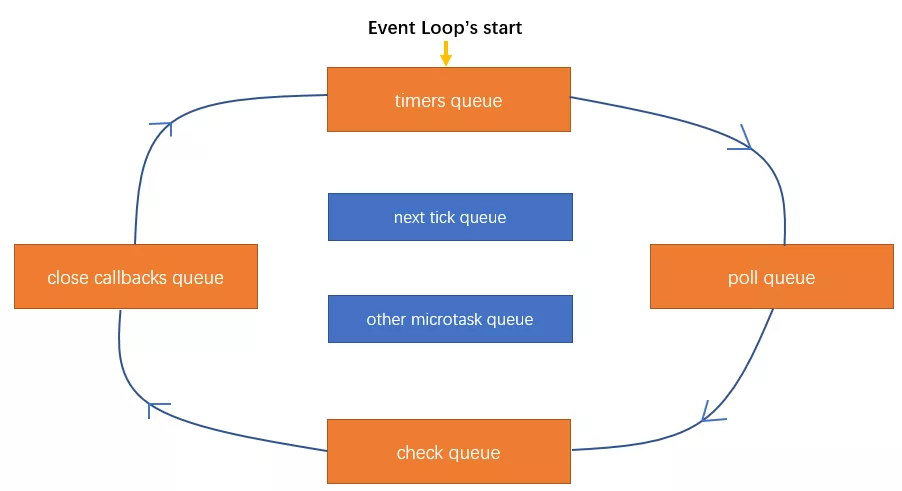
事件循环分阶段执行顺序
Section titled “事件循环分阶段执行顺序”通过 Node 的官方文档可以得知,其事件循环的顺序分为以下六个阶段,每个阶段都会处理专门的任务(优先级从高到低):
-
Timers Callback:涉及到时间,肯定越早执行越准确,所以这个优先级最高很容易理解,比如setTimeout, setInterval的回调函数就是在这个阶段进行处理的; -
Pending Callback:处理网络、IO等异常时的回调,有的*niux(linux, ...)系统会等待发生错误的上报,所以得处理下,例如TCP异常; -
Idle, Prepare:Node内部使用,不用做过多的了解; -
Poll Callback:处理IO的data,网络的connection,服务器主要处理的就是这个;例如:
const { readFile } = require("fs");const { resolve } = require("path");readFile(resolve(__dirname, "helloWorld.txt"),{ encoding: "utf-8" },(err, data) => {if (err) return;console.log(data);},); -
Check Callback:执行setImmediate的回调; -
Close Callback:关闭资源的回调,优先级最低,比如socket.destroy();
以上六个阶段,我们需要重点关注的只有四个,分别是: Timers Callback, Poll Callback, Check Callback, Close Callback。
这四个阶段都有各自的宏任务队列,我们分别将其称为timers queue, poll queue, check queue, close callbacks queue;
然后存在两个微任务队列,分别是 next tick queue, other microtask queue,其中next tick queue是Node为process.nextTick单独提供的微任务队列,优先级比其他微任务更高。即若同时存在 process.nextTick 和 promise.then(catch, finally...),则会先执行前者;
也就是说Node的事件循环执行顺序大致如下图:
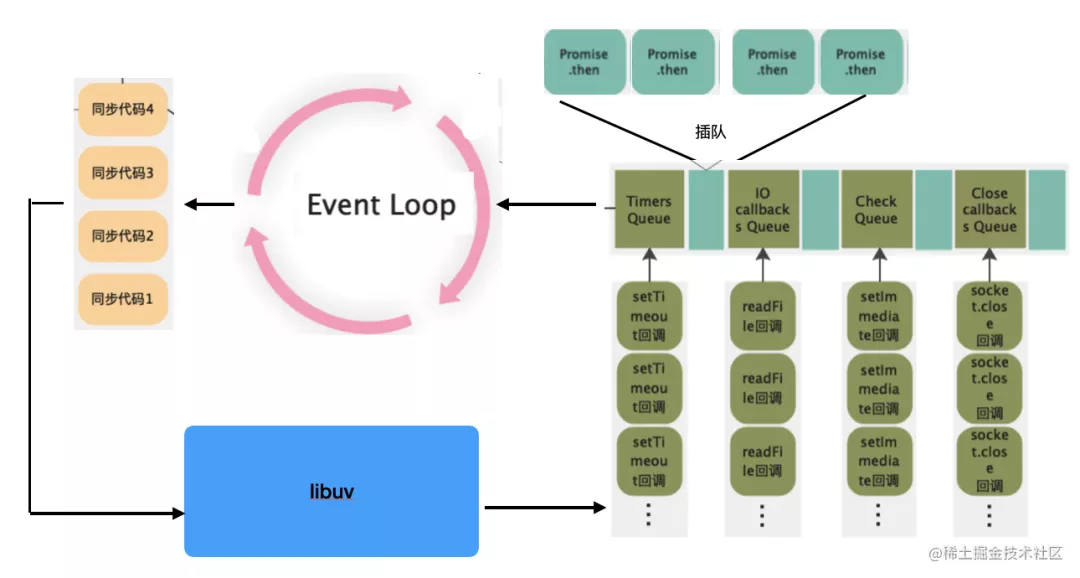
这里有一点我们需要关注,Node.js 的 Event Loop 并不是浏览器那种一次执行一个宏任务,然后执行所有的微任务,然后开启下一轮事件循环;而是执行完一定数量的宏任务,再去执行所有的微任务,然后进入下一个阶段的宏任务队列,然后再开始;
大致执行顺序:
- 先执行
timers queue中一定数量的宏任务,执行完之后; - 清空微任务队列:
next tick queue --> other microtask queue,清空完之后,或者直接微任务队列本身就没有微任务,进入下一个阶段; - 执行
poll queue中一定数量的宏任务,执行完之后; - 重复步骤
2; - 执行
check queue中一定数量的宏任务,执行完之后; - 重复步骤
2; - 执行
close callbacks queue中一定数量的宏任务,执行完之后; - 重复步骤
2; - 一轮事件循环结束,开启下一轮,进入步骤
1;
注意:上述步骤是针对Node 11之前,在 Node 11之后,对宏任务队列的执行有所改变,从之前的一次执行一定数量的宏任务改为一次只执行一个宏任务,然后就去清空微任务中的队列;
一定数量的宏任务特指什么
Section titled “一定数量的宏任务特指什么”这里的一定数量的宏任务你是否有一定的疑惑,接下来我举一个例子你就明白了:
setTimeout(() => { console.log("timer1"); Promise.resolve().then(function () { console.log("promise1"); });}, 500);
setTimeout(() => { console.log("timer2"); Promise.resolve().then(function () { console.log("promise2"); });}, 500);对于浏览器而言,它的事件循环的执行顺序为执行一个宏任务,然后就去清空微任务队列,然后在开始执行下一个宏任务,
- 最先开始的是一个宏任务,那就是执行这个
JS脚本代码,将两个setTimeout的回调扔进定时器线程处理,然后去清空微任务队列中的任务,发现里面微任务队列已经为空,开始下一轮事件循环; - 等待
500ms后,定时器处理线程将两个回调放到宏任务队列中,然后JS执行栈先调用第一个setTimeout的回调,先输出timer1,然后执行Promise,将其扔给异步线程处理,等待Promise状态发生变化,后面立即调用resolve,于是状态立即发生变化,于是异步线程将then(xx)扔进微任务队列中,setTimeout回调执行完了,然后检查微任务队列,发现里面有then(xx),输出promise1; - 差不多重复步骤
2,然后输出timer2, promise2;
因此它的执行结果为:
timer1, promise1, timer2, promise2
对于Node 11之后的版本执行结果和浏览器中执行结果相同。
但是针对Node 11之前的版本呢,它是执行一定数量的宏任务,比如这里的定时器的回调是在timer queue中,Node可能先将这两个回调执行完之后,然后再清空微任务队列,因此结果可能为:
timer1, timer2, promise1, promise2
setTimeout 一定比 setImmediate 早吗
Section titled “setTimeout 一定比 setImmediate 早吗”根据Node对事件循环阶段的划分,setTimeout是属于timer阶段的宏任务,而setImmediate 是属于check阶段的宏任务,它们处在不同的宏任务队列,这里我们将其分别称之为:timer queue, check queue;
理论上来说,按照事件循环执行顺序,timer queue比check queue执行要早,接下来看一段代码:
setTimeout(() => { console.log("setTimeout");}, 0);
setImmediate(() => { console.log("setImmediate");});这里多次执行,却出现了两种结果:
setTimeout, setImmediate(正常执行顺序);setImmediate, setTimeout(异常);
这是为什么呢?
原因是因为setTimeout的计时并不是精确的,往往会晚于计时,比如即使指定为0ms,它的时间也是大于0ms的,这就意味着,setTimeout(callback, 0)的callback并不一定会在当前事件循环的timer queue中,而是在下一轮事件循环中。
因此出现第二种执行结果的原因就是setImmediate的回调所在的check queue的事件循环要早于setTimeout的回调所在的timer queue的事件循环。
那如何解决上述问题呢?让两者在同一轮事件循环被读取调用即可。
方案 1:
setTimeout(() => { console.log("setTimeout");}, 0);
setImmediate(() => { console.log("setImmediate");});
// 让同步执行的代码的时间大于 `setTimeout` 时间精确度的误差let start = Date.now();while (Date.now() - start < 20) {}我们虽然无法改变setTimeout的计时误差,让其精确进入任务队列,但是我们可以延迟下一轮事件循环的开始时机。
这个延迟的时间只要能够让下一轮事件循环开始执行timer queue之前,将setTimeout的回调扔到timer queue中即可,这样就能让其它就能和setImmediate的回调在同一轮事件循环被执行调用。
方案 2:
const { readFile } = require("fs");const { resolve } = require("path");readFile( resolve(__dirname, "helloWorld.txt"), { encoding: "utf-8" }, (err, data) => { if (err) return; setTimeout(() => { console.log("setTimeout"); }, 0);
setImmediate(() => { console.log("setImmediate"); }); },);这里我们知道,IO的data是在事件循环的poll阶段执行的,此时当前事件循环已经过了timer阶段,因此只有在下一轮事件循环才会再次执行timer。
这样也就达到了让setTimeout的回调和setImmediate的回调在同一个事件循环中执行的效果。
但是这里的前提是:两轮事件循环的间隔,要大于setTimout的计时误差(事件循环一般也有一个启动时间,这个时间一般情况下是大于setTimout的计时误差)。